Hadoop核心组件之分布式文件系统HDFS
源自于Google的GFS论文,论文发表于2003年10月
HDFS是GFS的克隆版
- HDFS特点:扩展性&容错性&海量数据存储
- 将文件切分成指定大小的数据块(一般为128M)并以多副本的存储在多个机器上(也就是容错性)
- 数据切分、多副本、容错等操作是对用户是透明的(用户端看起来只要操作一个文件就行了)
- Namenode(Filename,numReplicas,block-ids,…)
- /users/sameerp/data/part/part-0,r:2,{1,3}
- /users/sameerp/data/part/part-1,r:3,{2,4,5}
Hadoop核心组件之资源调度系统YARN
- YARN:Yet Another Resource Negotiator
- 负责整个集群资源的管理和调度
- YARN特点:扩展性&容错性&多框架资源统一调度
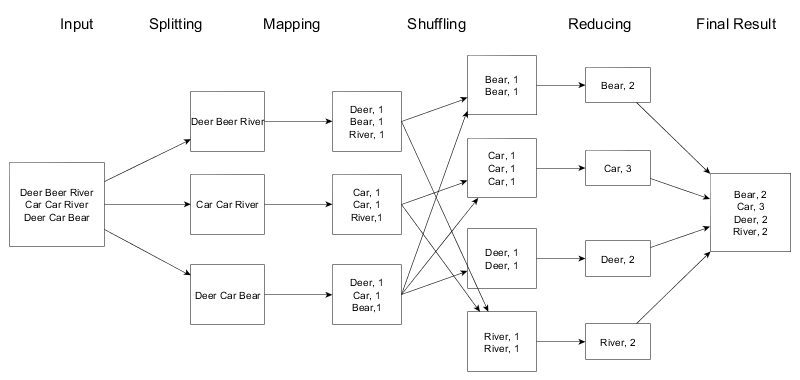
Hadoop核心组件之分布式计算框架MapReduce
- 源自于Google的MapReduce论文,论文发表于2004年12月
- MapReduce是Google MapReduce的克隆版
- MapReduce特点:扩展性&容错性&海量数据离线处理
Hadoop优势
Hadoop优势之高可靠性
- 数据存储:数据块多副本
- 数据计算:重新调度作业计算(发生异常后)
Hadoop优势之高扩展性
- 存储/计算资源不够时,可以横向的线性扩展机器
- 一个集群中可以包括数以千计的节点
Hadoop优势之其他
- 存储在廉价机器上,降低成本
- 成熟的生态圈
狭义Hadoop VS 广义Hadoop
狭义的Hadoop
是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台
广义Hadoop
指的是Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,hadoop是其中最重要最基础的一个部分;生态系统中的每一个子系统只解决一个特定的问题域(甚至可能很窄),不搞统一型的一个全能系统,而是小而精的多个子系统;
Hadoop常用发行版及选型
- Apache Hadoop
- CDH:Cloudera Distributed Hadoop(能够规避掉各module的冲突)
- HDP:Hortonworks Data Platform
