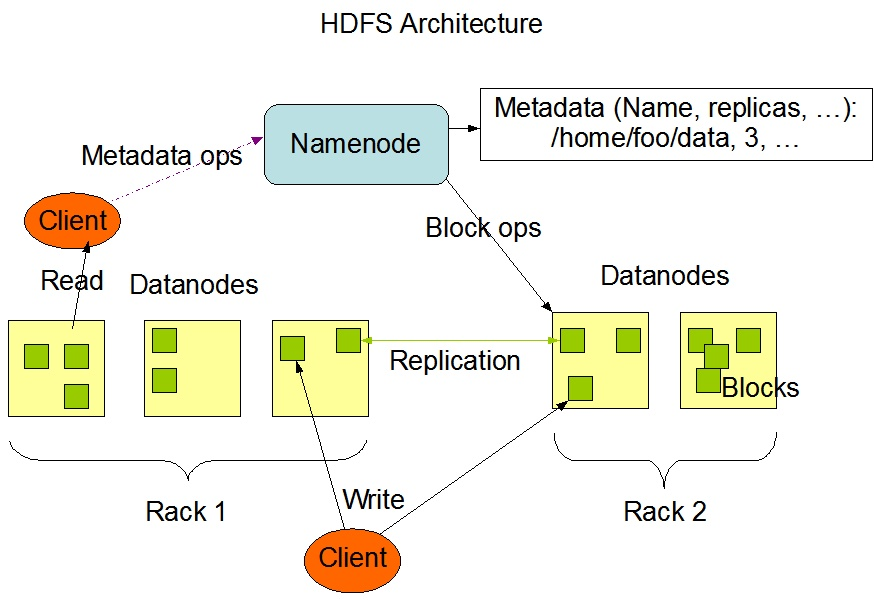
HDFS架构
1 Master(NameNode/NN) 带 N个Slavers(DataNode/DN)
HDFS/YARN/HBASE
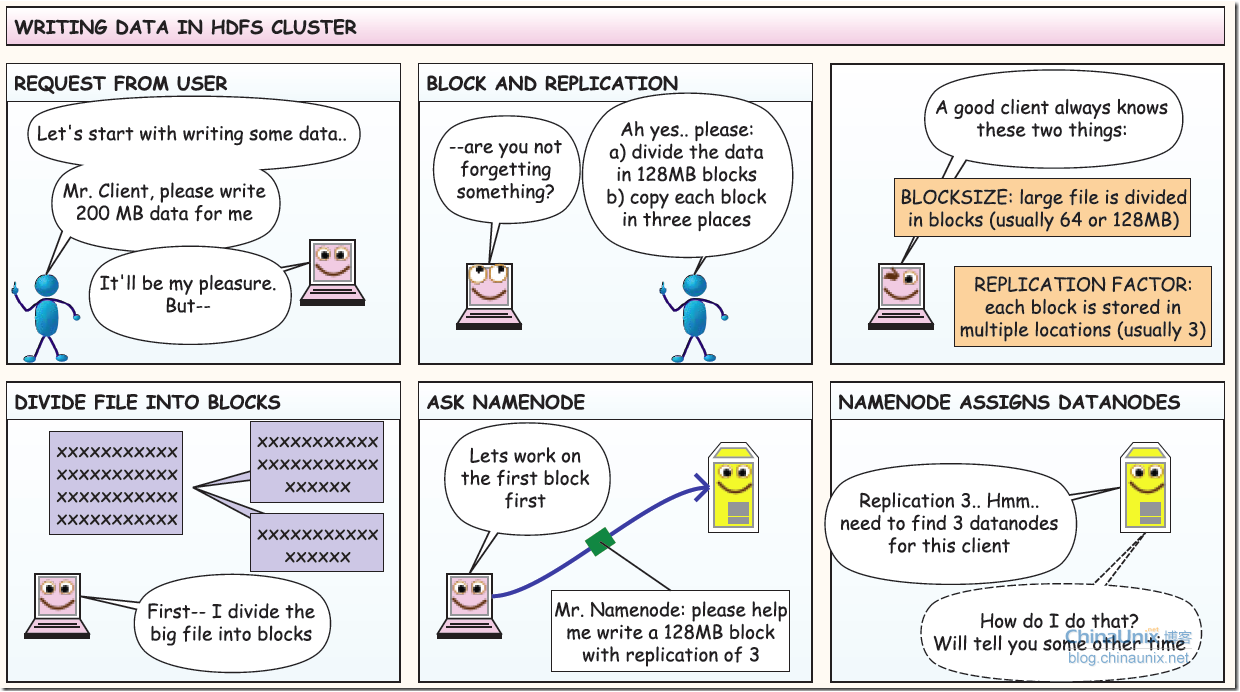
一个文件会被拆分为多个Block
blocksize:128M
130M===>2个Block:128M和2M
NameNode(NN)
- 负责客户端请求的响应
- 负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DataNode(DN)
- 存储用户的文件对应的数据块(Block)
要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
A typical deploymenthas a dedicated machine that runs only the NameNode software. Each of the othermachines in the cluster runs one instance of the DataNode software
The architecture doesnot preclude running multiple DataNodes on the same machine but in a realdeployment that is rarely the case.
NameNode + N个DataNode
建议:NameNode和DataNode部署在不同的节点上
副本机制
replicationfactor:副本因子
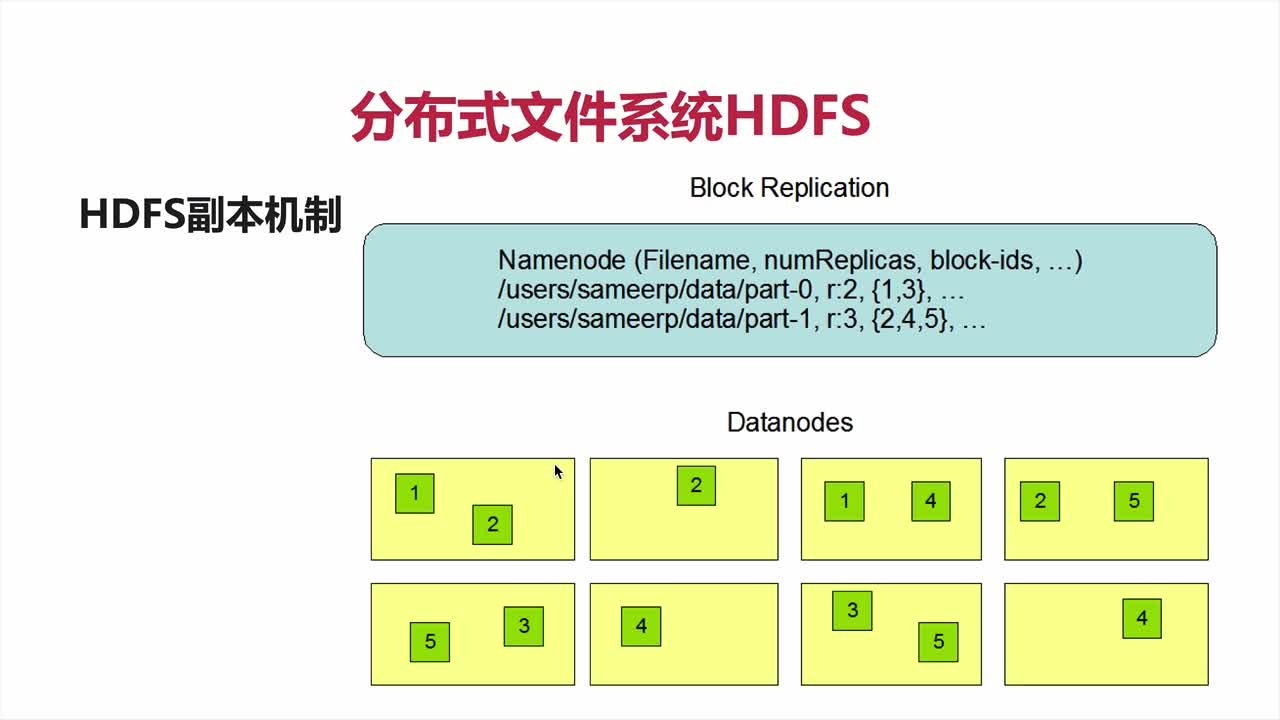
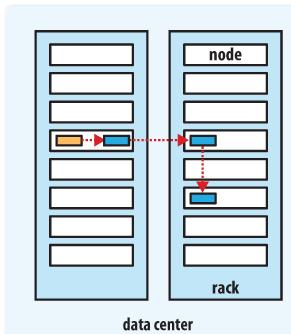
HDFS副本存放策略
第一个block副本放在和client所在的node里(如果client不在集群范围内,则这第一个node是随机选取的,当然系统会尝试不选择哪些太满或者太忙的node)。
第二个副本放置在与第一个节点不同的机架中的node中(随机选择)。
第三个副本和第二个在同一个机架,随机放在不同的node中。
HDFS shell常用命令的使用
- ls
- mkdir
- put
- get
- rm
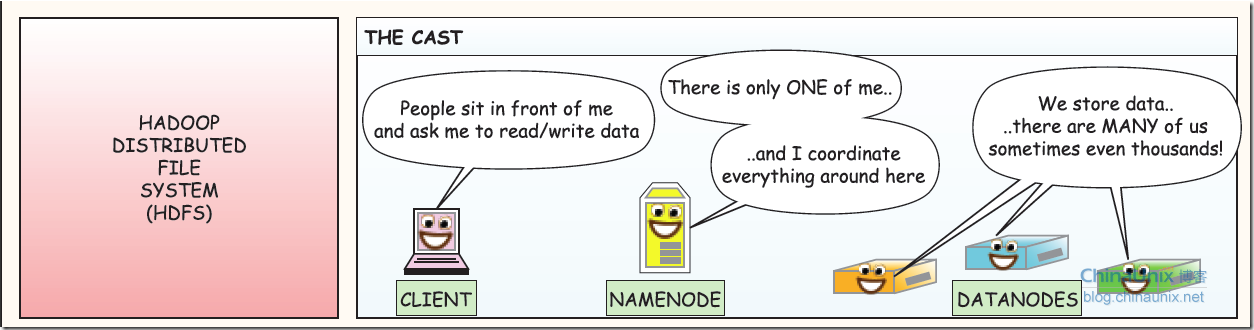
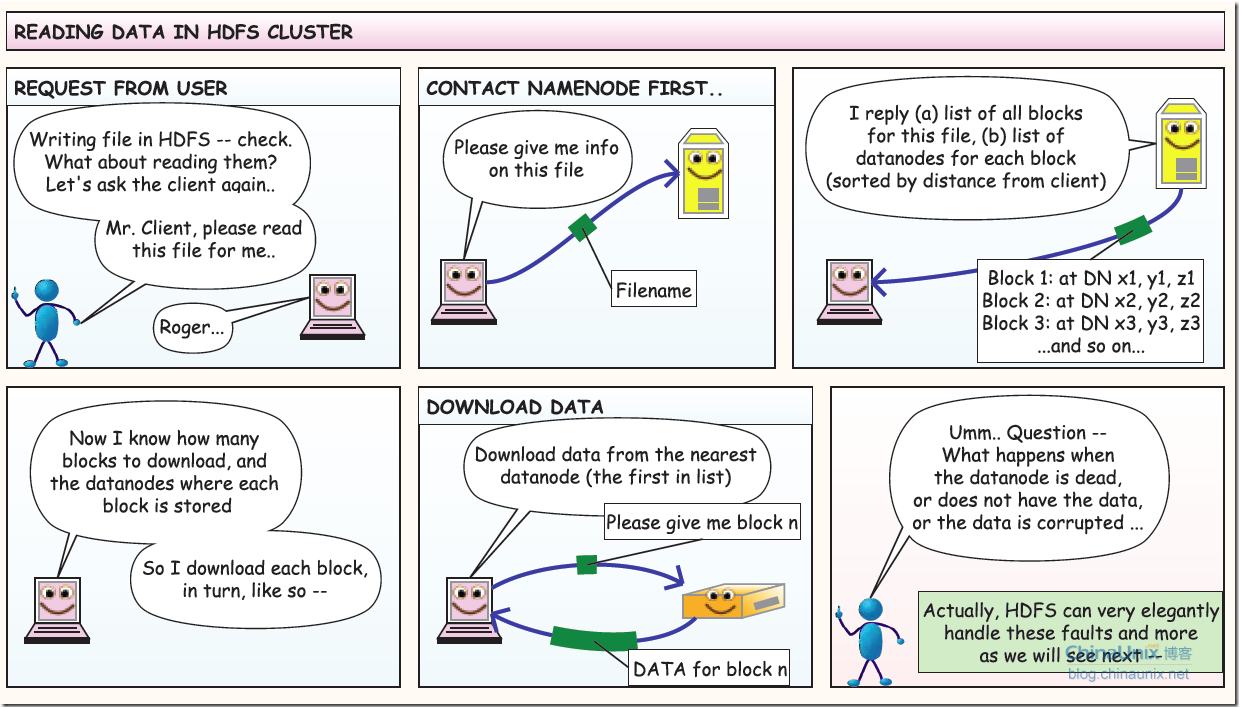
HDFS读写流程
三个部分
客户端、namenode(可理解为主控和文件索引类似linux的inode)、datanode(存放实际数据的存server)
如何写数据过程

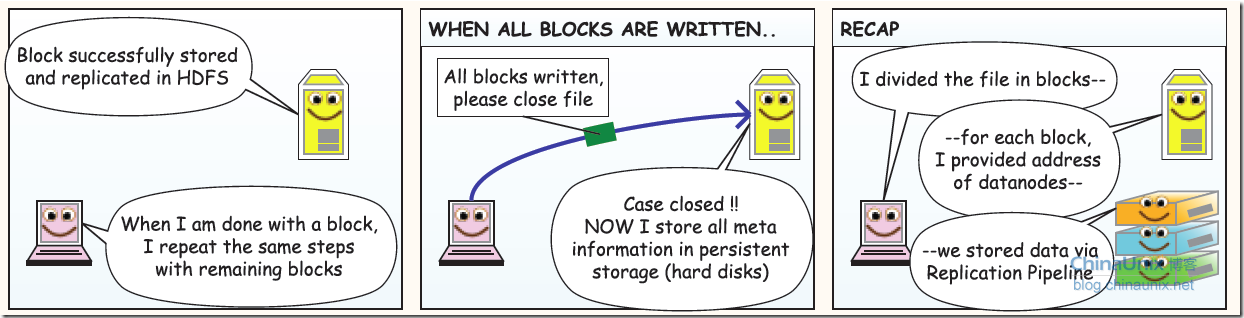
读取数据过程
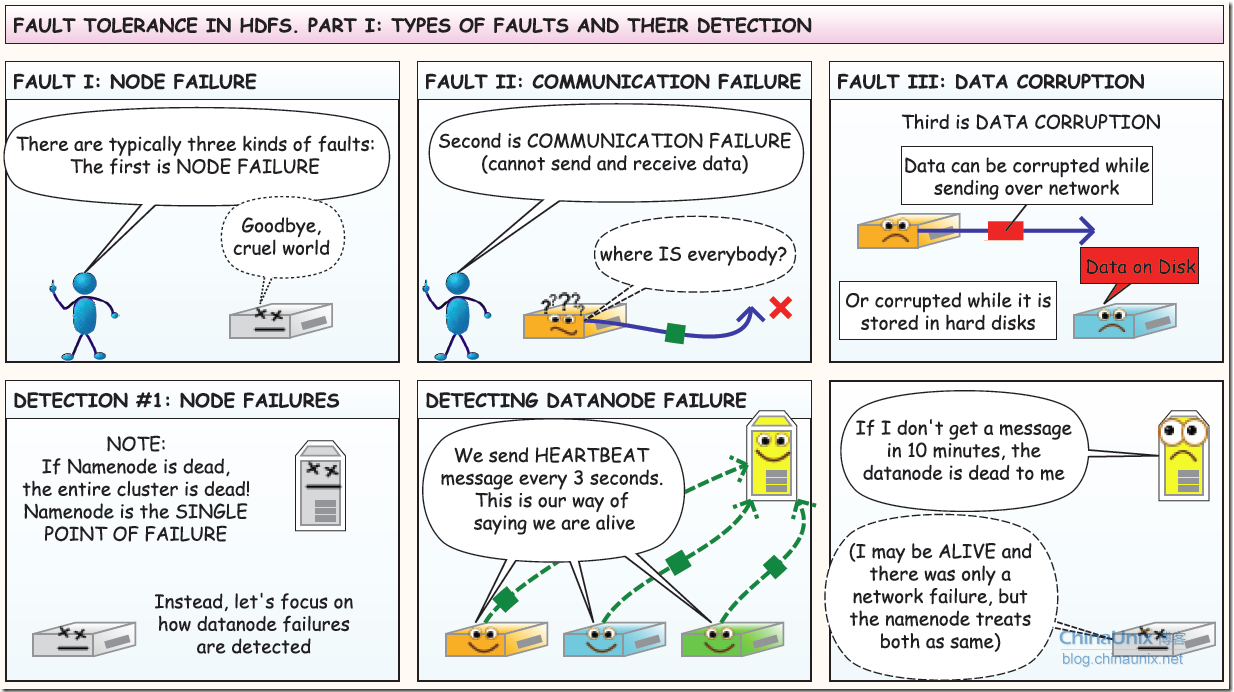
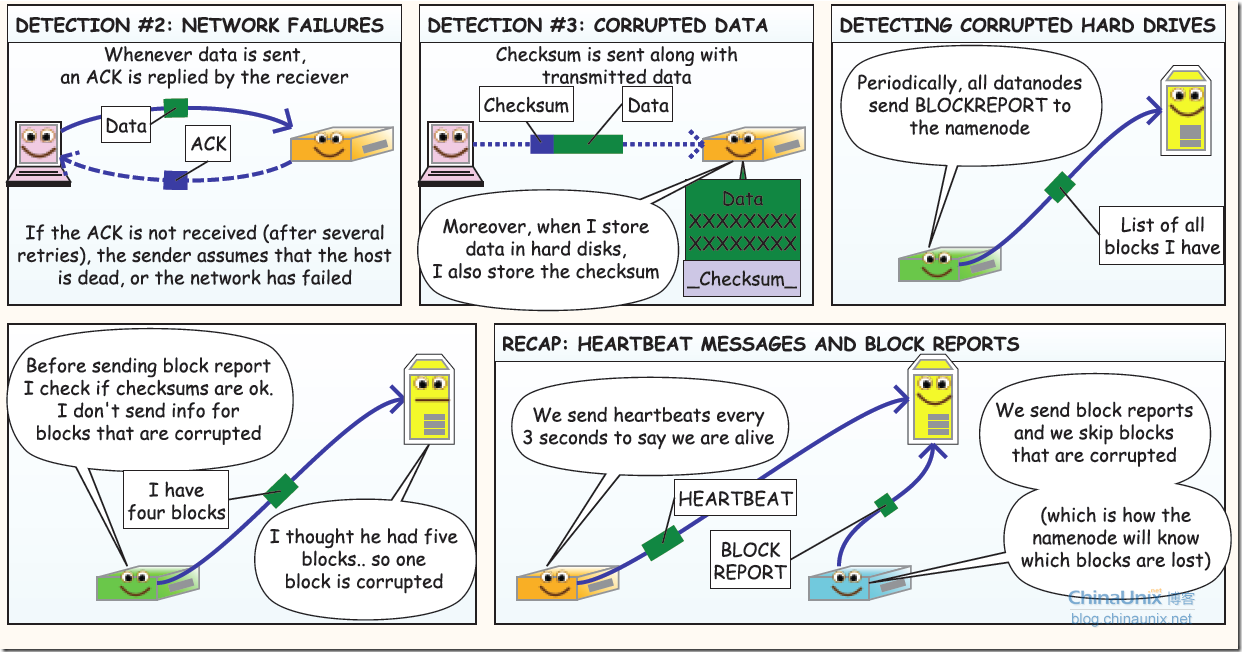
容错
第一部分:故障类型及其检测方法(nodeserver故障,和网络故障,和脏数据问题)