最近在看一些关于图网络的内容,初步入坑…之前看过那几篇赫赫有名的综述论文,看过后一个感觉:GNN是一个筐,什么都能往里面装。确实,这块很有研究价值,总的来讲就是使得机器学习能够处理Non Euclidean data。比如推荐系统、电子交易、计算几何、脑信号、分子结构等抽象出的图谱。这些图谱结构每个节点连接都不尽相同,有的节点有三个连接,有的节点有两个连接,是不规则的数据结构。以前机器学习只能处理Euclidean data,这类数据最显著的特征就是有规则的空间结构,比如图片是规则的正方形栅格,比如语音是规则的一维序列。而这些数据结构能够用一维、二维的矩阵表示,卷积神经网络处理起来很高效。

介绍
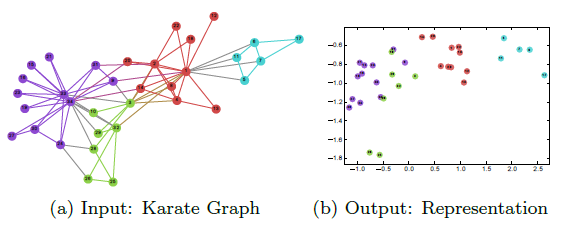
文章简介部分介绍了网络嵌入是什么,以社交网络为例,网络嵌入就是将网络中的点用一个低维的向量表示,并且这些向量要能反应原先网络的某些特性,比如如果在原网络中两个点的结构类似,那么这两个点表示成的向量也应该类似。文中以Karate network数据为例,效果见下图:
本文提出了一种网络嵌入的方法叫DeepWalk,它的输入是一张图或者网络,输出为网络中顶点的向量表示。DeepWalk通过截断随机游走(truncated random walk)学习出一个网络的社会表示(social representation),在网络标注顶点很少的情况也能得到比较好的效果。并且该方法还具有可扩展的优点,能够适应网络的变化。
我个人理解可以将这个过程理解为一个降维的过程,但是不同于传统意义上的高纬度降到低纬度,而是将一个复杂的结构降到低纬度。或者说可以理解为,将网络中的拓扑结构,嵌入到一个低维向量中,每个节点的低维向量,从某种程度上反应了该节点在网络中的连接情况。
这样做的好处
前面也讲了,目前机器学习也只能够处理一些Euclidean data,网络这种Non Euclidean data是无能为力的,主要是这类的数据不是我们常规的机器学习方法所能够处理的数据,那么很自然的想法就是将网络这种数据转换为我们机器学习能够处理的数据,然后就可以进行机器学习里面的常见比如分类、聚类、回归,这篇文章提到的DeepWalk算法也可以说是在深度学习火热的今天在Graph Embedding的开山之作了。
例如网络中的社团发现算法,大多数情况下我们都针对网络做大量的游走,不断改变网络的社团结构,以使网络获得最优的模块度,但是如果我们能将拓扑信息嵌入到低维向量中,那么每个节点我们都可以看做是一个样本,每个维度都可以看做一个feature,那么只需要跑个聚类算法,就可以得到很好的结果。除了聚类,还有链路预测、推荐等一系列网络中的问题,都可以直接扔到机器学习的相关算法中跑出来。
问题定义
图G定义如下,由顶点集V和边集E组成:
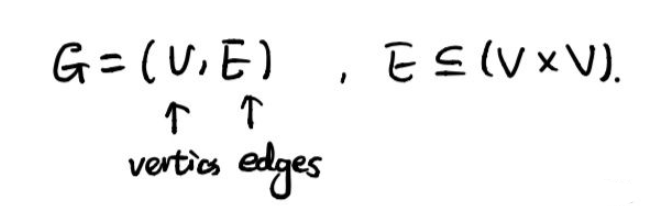
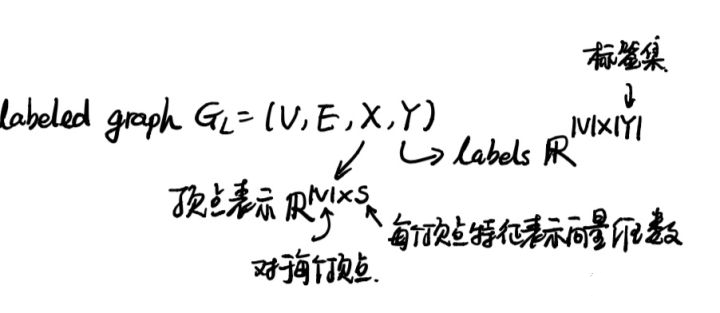
如果在图G的基础上再加上顶点的向量表示和顶点所属的标注(网络节点分类问题中,网络中的每个顶点都有一个类别,所属的类别即为该顶点的标注)就构成了一个标注图(labeled graph)。顶点的表示X是一个|V|×s维的矩阵,|V|表示顶点的数量,s是代表每个顶点的向量的维数(一般比较小),所以X即为将每个顶点的向量结合在一起形成的矩阵。Y则是每个顶点的标注构成的矩阵。
学习社会表示
首先给出我对这种方法的理解:dedpwalk的主要思想是类比word2vec的方法,将一系列的walks作为自己的语料库,而将图中的节点作为自己的词汇表,然后运用word2vec的方法得到节点向量表示(也就是社会表示)。
文中提到社会表示具有如下特性
- 适应性,网络表示必须能适应网络的变化。网络是一个动态的图,不断地会有新的节点和边添加进来,网络表示需要适应网络的正常演化。
- 属于同一个社区的节点有着类似的表示。网络中往往会出现一些特征相似的点构成的团状结构,这些节点表示成向量后必须相似。
- 低维。代表每个顶点的向量维数不能过高,过高会有过拟合的风险,对网络中有缺失数据的情况处理能力较差。
- 连续性。低维的向量应该是连续的。
于是作者提出了一个思路,针对每个节点跑了个随机游走,游走过程中就得到了一系列的有序节点序列,这些节点序列可以类比于文章的句子,节点类比于句子中的单词,然后再使用word2vec跑,得到对应的向量。
上边的思路可行不可行,重点是要证明网络中的节点与文本中的词相似不相似,于是作者针对YouTube的社交网络与Wikipedia的文章进行了研究,比较了在短的随机游走中节点出现的频度与文章中单词的频度进行了比较,可以得出二者基本上类似。(说实话我不是很理解这样的比较有什么意义,可能我对word2vec理解的不够。确实两个图比较相似,这个就是证明了一下Zipf’s law,关键能不能用word2vec取决于这个吗?)
算法核心部分
提到网络嵌入,可能会让人联想到NLP中的word2vec,也就是词嵌入(word embedding)。前者是将网络中的节点用向量表示,后者是将单词用向量表示。因为大多数机器学习的方法的输入往往都是一个向量,算法也都基于对向量的处理,从而将不能直接处理的东西转化成向量表示,这样就能利用机器学习的方法对其分析,这是一种很自然的思想。
本文处理网络节点的表示(node representation)就是利用了词嵌入(词向量)的的思想。词嵌入的基本处理元素是单词,对应网络网络节点的表示的处理元素是网络节点;词嵌入是对构成一个句子中单词序列进行分析,那么网络节点的表示中节点构成的序列就是随机游走。
所谓随机游走(random walk),就是在网络上不断重复地随机选择游走路径,最终形成一条贯穿网络的路径。从某个特定的端点开始,游走的每一步都从与当前节点相连的边中随机选择一条,沿着选定的边移动到下一个顶点,不断重复这个过程。下图所示绿色部分即为一条随机游走。
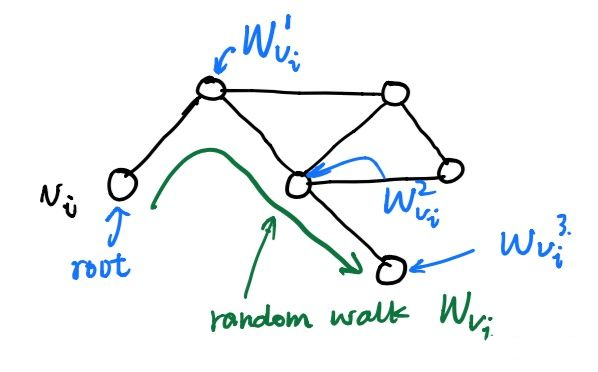
关于随机游走的符号解释:以$v_{i}$为根节点生成的一条随机游走路径(绿色)为$W_{v_{i}}$,其中路径上的点(蓝色)分别标记为 $W_{v_{i}}^{1}, W_{v_{i}}^{2}, W_{v_{i}}^{3} \ldots$,截断随机游走(truncated random walk)实际上就是长度固定的随机游走。
使用随机游走有两个好处:
- 并行化,随机游走是局部的,对于一个大的网络来说,可以同时在不同的顶点开始进行一定长度的随机游走,多个随机游走同时进行,可以减少采样的时间。
- 适应性,可以适应网络局部的变化。网络的演化通常是局部的点和边的变化,这样的变化只会对部分随机游走路径产生影响,因此在网络的演化过程中不需要每一次都重新计算整个网络的随机游走。
首这部分内容需要理解词向量模型这一块的内容:(这部分如果不懂的话可以看我之前写的一篇博客)
如果将单词对应成网络中的节点$v_{i}$,句子序列对应成网络的随机游走,那么对于一个随机游走 $\left(v_{0}, v_{1}, \ldots, v_{i}\right)$要优化的目标就是:$\operatorname{Pr}\left(v_{i} |\left(v_{0}, v_{1}, \ldots, v_{i-1}\right)\right)$
按照上面的理解就是,当知道$\left(v_{0}, v_{1}, \ldots, v_{i-1}\right)$游走路径后,游走的下一个节点是$v_i$的概率是多少?可是这里的$v_i$是顶点本身没法计算,于是引入一个映射函数$\Phi$,它的功能是将顶点映射成向量(这其实就是我们要求的),转化成向量后就可以对顶点$v_i$进行计算了。
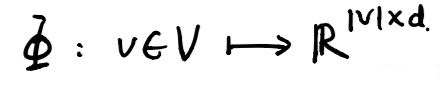
映射函数$𝚽$对网络中每一个节点映射成d维向量,$𝚽$实际上是一个矩阵,总共有|V|×d个参数,这些参数就是需要学习的。
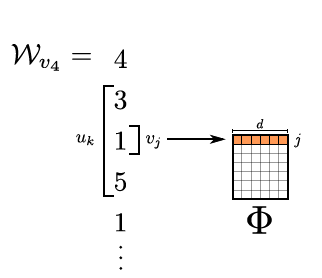
有了$𝚽$之后,$\mathbf{\Phi}\left(v_{i}\right)$就是一个可以计算的向量了,这时原先的优化目标可以写成:
$\operatorname{Pr}\left(v_{i} |\left(\mathbf{\Phi}\left(v_{0}\right), \mathbf{\Phi}\left(v_{1}\right), \ldots, \mathbf{\Phi}\left(v_{i}-1\right)\right)\right)$
但是怎么计算这个概率呢?同样借用词向量中使用的skip-gram模型
skip-gram模型有这样3个特点:
- 不使用上下文(context)预测缺失词(missing word),而使用缺失词预测上下文。因为 $\left(\mathbf{\Phi}\left(v_{0}\right), \mathbf{\Phi}\left(v_{1}\right), \ldots, \mathbf{\Phi}\left(v_{i}-1\right)\right)$ 这部分太难算了,但是如果只计算一个 $\mathbf{\Phi}\left(v_{k}\right)$,其中$v_k$是缺失词,这就很好算。
- 同时考虑左边窗口和右边窗口。下图中橘黄色部分,对于$v_4$同时考虑左边的2个窗口内的节点和右边2个窗口内的节点。
- 不考虑顺序,只要是窗口中出现的词都算进来,而不管它具体出现在窗口的哪个位置。
应用skip-gram模型后,优化目标变成了这样:

其中概率部分的意思是,在一个随机游走中,当给定一个顶点$v_i$时,出现它的w窗口范围内顶点的概率。

做了这样的处理后可以发现,忽视顶点的顺序更好地体现了在随机游走中顶点的邻近关系,并且只需要计算一个顶点的向量,减少了计算量。所以DeepWalk是将截断随机游走与神经语言模型(neural language model)结合形成的网络表示,它具有低维、连续和适应性特征。
整个DeepWalk算法包含两部分,一部分是随机游走的生成,另一部分是参数的更新。
算法的流程如下:

其中第2步是构建Hierarchical Softmax,第3步对每个节点做γ次随机游走,第4步打乱网络中的节点,第5步以每个节点为根节点生成长度为t的随机游走,第7步根据生成的随机游走使用skip-gram模型利用梯度的方法对参数进行更新。
参数更新的细节如下:

