对于大多数人来说,犯错是一件让人很不开心的事情。但反过来想,犯错可以让我们意识到自己的不足,然后我们很快就学会下次不能再犯错了。犯的错越多,我们学习进步就越快。
同样的,在神经网络训练当中,当神经网络的输出与标签不一样时,也就是神经网络预测错了,这时我们希望神经网络可以很快地从错误当中学习,然后避免再预测错了。那么现实中,神经网络真的会很快地纠正错误吗?
我们来看一个简单的例子:
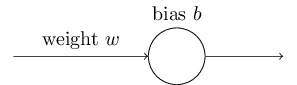
上图是一个只有一个神经元的模型。我们希望输入1的时候,模型会输出0(也就是说,我们只有一个样本(x=1, y=0))。假设我们随机初始化权重参数w=2.0,偏置参数b=2.0。激活函数为sigmoid函数。所以模型的第一次输出为:
可见,模型的第一次输出跟标签相差很大,很错误的一个输出。然后我们不断地使用梯度下降算法更新参数,重复训练。于是我们得到了下面这个图:

从图中可以看出,随着训练的次数增加,模型的输出越来越接近0。但是有没有发现一个问题?在训练的前部分,cost并没有显著的减少,也就是权重参数w和偏置参数b的变化不明显。我们前面说了,当我们知道错了,而且错误很大时,我们通常会很快地将错误降下来。但是图中的曲线一开始却是很缓慢地变化。这跟我们想要的不一样呀。虽然最终的结果是会收敛,但是我们希望的是在一开始训练的时候,模型可以收敛得更快。究竟是什么原因使得模型的cost在一开始的时候下降很慢呢?
我们知道在用梯度下降更新参数的时候,我们是计算了下面这两个偏导数:
其中:$C=\frac{(y-a)^{2}}{2}$,a为模型的输出。所以,上面说cost的变化不明显,也就是这两个偏导数的值很小。我们将a用上面计算output的公式代替,即$a=\sigma(z), z=w \cdot x+b$。我们就可以得到:
为了直观一点,我们可以看一下sigmoid函数的曲线图:

我们可以看到,当模型的输出a(sigmoid的输出)接近于1的时候,曲线变得很平滑(曲线的右上角),所以$σ′(z)$也就很小了(斜率很小)。因此,上面两个偏导数的结果就很小了。这就是为什么一开始cost曲线下降很慢的原因了。
交叉熵代价函数
那么,如何解决学习速度不够快这个问题呢?
要想解决这个问题,就是说我们的cost函数不能使用二次平方这种形式了。我们应该使用一种叫做交叉熵的函数。交叉熵代价函数的公式如下:
其中,n是训练样本的总数。从这个公式我们并不能很清晰地看出解决了学习速度慢的问题。我们对一个权重参数求导:
将上述公式继续化简可以得到:
我们知道$σ′(z)=σ(z)(1−σ(z))$,所以我们可以将上面的公式分子分母部分约掉,得到:
从这里我们就可以看到,权重参数的偏导数由$σ(z)−y$控制,模型的输出与标签y之间的偏差越大,也就是$σ(z)−y$的值越大,那么偏导数就会越大,学习就会越快。这正是我们想要的结果。我们用一开始那个例子,不错这一次cost函数使用交叉熵代价函数了,可以得到下面的曲线:

可以看到,这一次,在一开始的时候,曲线下降的速度变快了。这就是为什么我们在大部分的机器学习模型中,经常使用交叉熵函数作为代价函数的原因了。
